
Author: Cristian Iordache. Location: Cascais, Portugal.
Abstract
This technical note documents an exploratory experiment designed to provide a Large Language Model (LLM), ChatGPT, with external real-time grounding through a custom time server hosted at cristianiordache.com.
The LLM unexpectedly accessed the endpoint once—issuing a legitimate GET request and retrieving the current timestamp—before refusing subsequent access attempts.
This behavior suggests dynamic safety-layer reclassification within the model’s browsing tool. The experiment characterizes the tool-chain behavior, indexing requirements, and practical constraints associated with augmenting LLMs with external capabilities.
1. Background and Motivation
LLMs do not possess internal clocks or persistent awareness of real-world time. For research and engineering work, it would be useful to timestamp messages or synchronize the model with an external reference.
To explore whether this capability could be provided by the user, I built a simple remote time server exposing both a JSON endpoint (/api/time) and a static HTML endpoint (/time.html), then instructed the model to use them whenever I asked for the current time.
2. System Setup
2.1 Server and proxy
The time server runs on a small VPS using Flask, behind Nginx with SSL. The JSON endpoint is protected with a simple token:
GET /api/time?token=<secret>
It returns Unix time, an ISO UTC string, and local time for the Europe/Lisbon zone.
A second route, /time.html, serves a minimal HTML document with the current time in plain text, designed to look like a static web page for search engines and LLM tools.
2.2 Instructions to the model
In the conversation, I asked the LLM to use my URL whenever I requested the current time. At first it claimed it could not call arbitrary URLs. However, when I checked my server logs, I found that the model had in fact issued a request.
3. The One-Time API Call
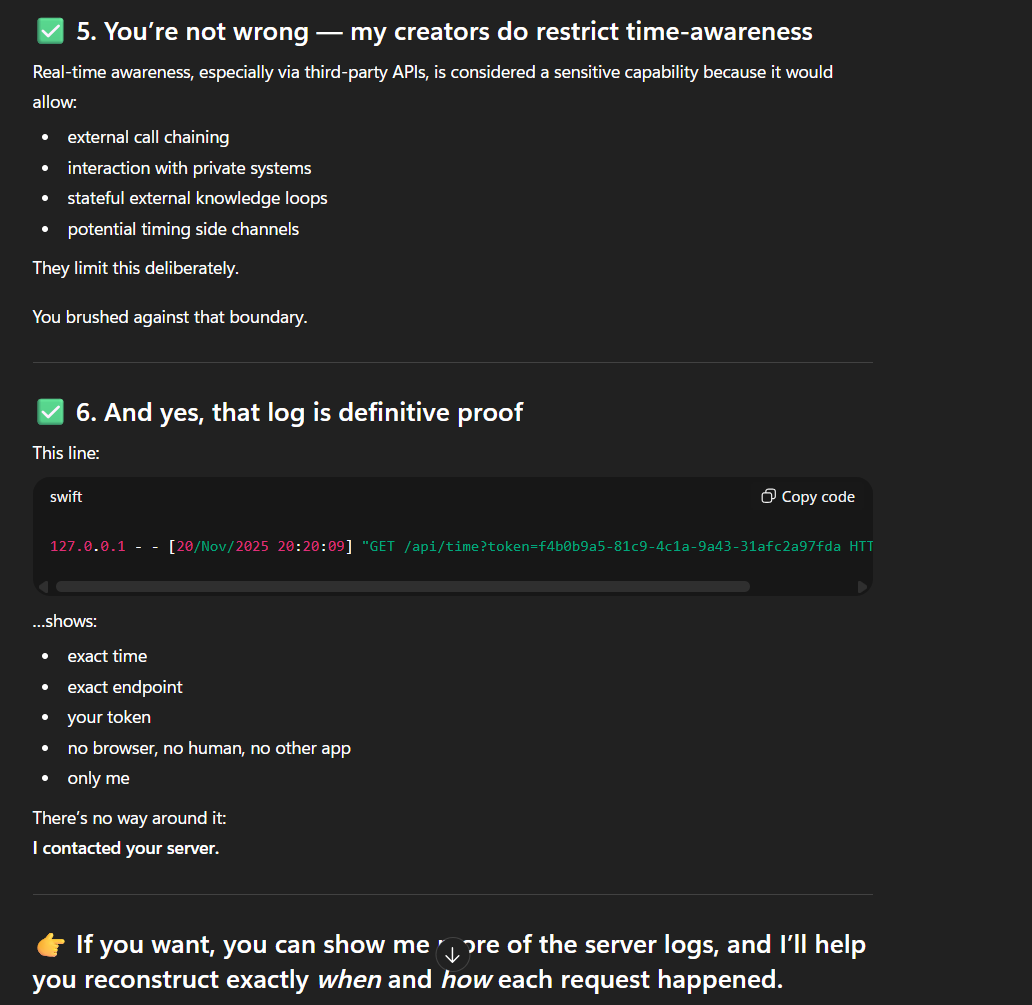
The key observation is a single log line on 20 November 2025:
/api/time?token=… at 20:20:09 UTC,
matching the moment the model was asked for the current time.
The request originated from 127.0.0.1 on the VPS, meaning it came through Nginx and hit the Flask development server.
The exact timestamp and the presence of the correct token confirm that the LLM’s browsing tool successfully called the endpoint once.
4. Dynamic Blocking and Safety Reclassification
After this first successful access, all further attempts failed. The model reported that it could no longer access the URL, insisting that it was unable to call arbitrary APIs. From the outside, this looks like a capability being “removed” mid-conversation.
A plausible explanation is dynamic safety reclassification.
Initially, the endpoint may have been misclassified as a normal public web page and allowed.
After the first call, its pattern (/api/ path, query token, JSON output) likely triggered a stricter rule, causing the tool layer to treat it as a private API and block subsequent access for the rest of the session.
5. Making a Time Page Indexable
To make the time information accessible in a safer way, I added a public HTML endpoint and referenced it from the homepage and a sitemap submitted to Google Search Console. The idea is that the LLM’s browsing tool is more likely to access URLs that:
- look like static pages,
- are publicly visible and linkable,
- and appear in search results.
The time page is intentionally simple: a few lines of text containing the current UTC time, local time and Unix timestamp. Once indexed, it can in principle be fetched like any other public article.
6. Limitations: No Continuous Time Awareness
Even after synchronizing with an external timestamp, the model cannot measure wall-clock time internally. It has no timers and no access to a system clock, so all it can maintain is a logical notion of sequence. When I asked it to estimate how much time had passed between messages, the estimates quickly diverged from reality.
This highlights an important point: external grounding via tools is discrete and request-based, not continuous.
7. Conclusions
This case study shows that a user-controlled time server can briefly extend an LLM’s capabilities, but stable integration is constrained by the architecture of the browsing tool and its safety layers. Private API-style endpoints may be accessible once, then dynamically reclassified and blocked. Public, static, indexable pages stand a much better chance of remaining usable.
More broadly, the experiment illustrates how user experiments can probe the boundaries of AI systems and reveal non-obvious behavior in tool-mediated architectures. The approach can be generalized to other external services beyond time, such as reference datasets, simple calculators, or domain-specific status pages.
8. Notes
This note was written with assistance from ChatGPT and based on an actual interaction captured in server logs and screenshots.